pySPACE
Signalverarbeitungs- und Klassifikationsumgebung in Python
Ansprechpartner/in:
pySPACE ist ein modulares Software-Framework für die Verarbeitung segmentierter Zeitreihen sowie Merkmalsvektoren. Es wurde speziell für die verteilte Verarbeitung und empirische Evaluation unterschiedlicher Signalverarbeitungsketten entwickelt. Es kann sowohl für große offline Vergleiche als auch online in konkreten Anwendungen benutzt werden. Verschiedene Datensätze werden automatisch geladen, verarbeitet und gespeichert. Signalverarbeitungsalgorithmen (Knoten) und größere Transformationen der Datensätze (Operationen) können einfach aneinander gehängt werden. Eine parallele Verarbeitung kann auf einem Mehrkernprozessor oder Cluster erfolgen. pySPACE wird aktiv gewartet und weiterentwickelt, wodurch die Anzahl von Knoten stetig steigt.
| Internetseite: | http://pyspace.github.io/pyspace/ |
| Schlüsselwörter: | Maschinelles Lernen, Signalverarbeitung, Parallelisierung |
| Status: | aktiv |
| Betriebssystem: | Linux, Mac OS X, Windows |
| Programmiersprachen: | Python |
| Lizenz: | GPL3 |
| Eigentumsrechte: | Diese Software wurde ursprünglich vom DFKI sowie der Arbeitsgruppe Robotik und der Universität Bremen entwickelt, wird aber jetzt auch von Dritten weiterentwickelt. Bei Fragen und Anregungen wenden sie sich an die Ansprechpartner. |
Softwarebeschreibung
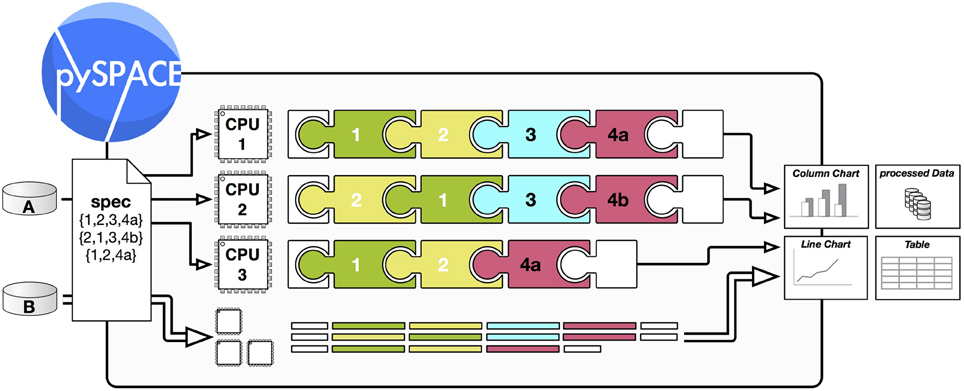
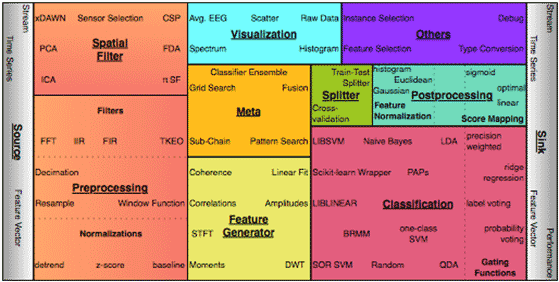
Knoten für Verarbeitungsketten
Eine modulare Verarbeitungskette beginnt immer mit dem Laden der Daten (Source) und endet mit dem Speichern oder Versenden der Daten (Sink). Eine übliche Verarbeitungskette für Gehirnstromdaten besteht zum Beispiel aus Trendentfernung, Downsampling, zeitliche Filterung, Dimensionsreduktion (ICA oder xDAWN), Merkmalsgenerierung, Normalisierung und der abschließenden Klassifikation. Zusätzlich können Daten und Algorithmen visualisiert werden oder Daten in Trainings- und Testdaten aufgespalten werden (Kreuzvalidierung). Einige Knoten können intern einen oder mehrere Knoten aufrufen um sie zu kombinieren, ihr Verhalten zu ändern oder deren Parameter zu optimieren. Die Parameteroptimierung erfolgt wiederum parallel.
Benutzbarkeit
- Einfache Installation und
- Einrichtung (zentrales Konfigurationsverzeichnis; notwendige Abhängigkeiten: Python, YAML, NumPy, SciPy; optionale Abhängigkeiten: matplotlib, scikit-learn, PyQt4, mpi4py, LIBSVM, LIBLINEAR, MDP, ...)
- Einfache Benutzung und Erweiterbarkeit
- Öffentlich verfügbare Dokumentation - Schnittstellen zu externen Bibliotheken (scikit-learn, Maja Machine Learning Framework, Weka)
- Interaktive Tools zur Auswertung und zur Generierung und Ausführung von Verarbeitungsketten

