VeryHuman
Lernen und Verifikation Komplexer Verhalten für Humanoide Roboter

Die Validierung von Systemen in sicherheitsrelevanten Situationen ist ein inhärent schwieriges Problem, wenn deren Verhalten über Lernalgorithmen trainiert wurde. Der subsymbolische Operationsmodus erlaubt keine ausreichende Abstraktion oder Repräsentation um Korrektheitsbeweise zu führen. Die Zielsetzung des Projektes VeryHuman ist es, die nötigen Abstraktionsebenen durch Beobachtung und Analyse des zweibeinigen Laufens eines humanoiden Roboters zu synthetisieren. Die zu entwickelnde Theorie dient sowohl als Grundlage, um Belohnungsfunktionen abzuleiten, die für die optimale Kontrolle des Roboters über erweiterte Lernansätze verwendet werden, als auch um verifizierbare Abstraktionen kinematischer Robotermodelle zu generieren, die erleichterte Verhaltensvalidierung erlauben.
Projektdetails
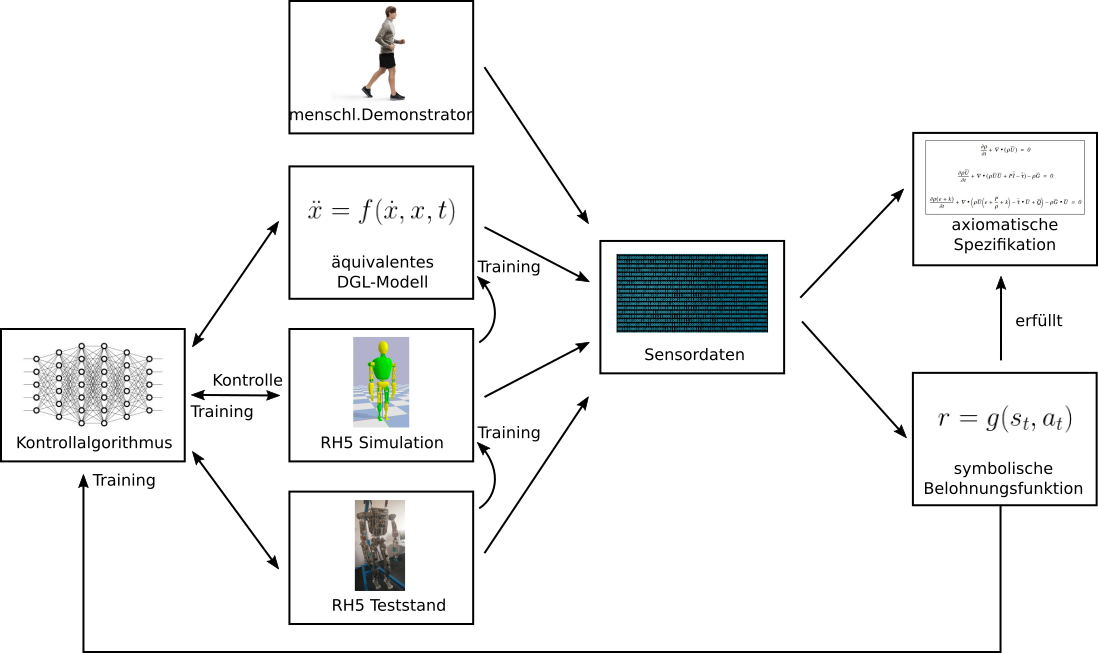
Biologisch inspirierte Kontrollalgorithmen wurden in jüngster Zeit erfolgreich für Robotersteuerung verwendet. Oft werden Techniken des bestärkenden Lernens oder der optimalen Kontrolltheorie verwendet, um komplexe Bewegungsabläufe mit einem Roboter durchzuführen (z.B. aufrechtes Gehen). Allerdings verbleiben bis dato zwei große Herausfoderungen für diese lernbasierten Ansätze:
- Robuste Roboterhardware und eine akkurate Simulation des Systems sind notwendig. Der Roboter kann beispielsweise nicht einer großen Anzahl holonomer Randbedingungen, unter anderem interne mechanisch geschlossene Schleifen und externe Kontakte, unterworfen sein, welche die Genauigkeit der Simulation beeinträchtigen.
- Zum Anderen kann sich die Implementierung Kontrollalgorithmen dieser Art schwierig gestalten, da es einer adäquaten Spezifikation des gesuchten Verhaltens bedarf. Am Beispiel des aufrechtes Ganges eines zweibeinigen humanoiden Roboters wird deutlich, dass es nicht direkt offensichtlich ist, was diese Spezifikation ist. Ein Ansatz ist die Relation verschiedener Körperteile zu betrachten (Kopf über Schultern, Schultern über Hüfte, Hüfte über Füßen) und physikalische Stabilitätskriterien zu untersuchen (Druckschwerpunkt, Zero Moment Point, etc.). Aber ist dies wirklich eine ausreichende Beschreibung des aufrechten Ganges, und was sind weitere, nicht-triviale Charakteristika? Die Beantwortung dieser Frage ist die Vorraussetzung, um passende Belohnungsfunktionnen und Randbedingungen für (tiefes) bestärkendes Lernen oder optimale Kontrolle zu formulieren.
Die drei Hauptforschungsfragen dieses Projektes sind:
- Wie können Verhaltenseigenschaften für einen komplexen humanoiden Roboter formuliert und bewiesen werden?
- Wie können Frameworks des bestärkenden Lernens und der optimalen Kontrolle effizient kombiniert werden um das gewünschte Verhalten zu erzielen?
- Wie können aus Verhaltensbeschreibungen Belohnungsfunktionen abgeleitet werden, so dass diese in dem komplexen Anwendungsfall des aufrechten Gehens für bestärkendes Lernen und optimale Kontrollansätze verwendet werden können?
Diese drei Forschungsfragen sind eng verwoben und werden in drei Projektbereichen bearbeitet. Das übergreifende Projektziel ist eine Methodologie zur Entwicklung eines hybriden Kontrollansatzes aus optimaler Kontrolle und bestärkendem Lernen, zusammen mit einer rationalen Rekonstruktion des beobachteten sowie zukünftigen Verhaltens. Diese Rekonstruktion basiert auf Beobachtung der Roboterbewegungen und grundlegender Kenntnis der Physik (Strarrkörperdynamik). Der generelle Ansatz ist in Fig 2 skizziert. Das Demonstrationsszenario beinhaltet die Anwendung der entwickelten Methodologie für den aufrechten Gang des Roboters “RH5”, einer Neuentwicklung des DFKI-RIC (Fig. 1)
Videos
RicMonk: Ein dreigliedriger Hangelroboter mit passiven Greifern für eine energieeffiziente Hangelbewegung
In diesem Beitrag werden das Design, die Analyse und die Leistungsbewertung von RicMonk vorgestellt, einem neuartigen dreigliedrigen Hangelroboter, der mit passiven hakenförmigen Greifern ausgestattet ist. Das Hangeln, eine wendige und energieeffiziente Art der Fortbewegung, die bei Primaten beobachtet wird, hat die Entwicklung von RicMonk inspiriert, um vielseitige Fortbewegung und Manöver auf leiterartigen Strukturen zu erforschen. Die anatomische Ähnlichkeit des Roboters mit Gibbons und die Integration eines Schwanzmechanismus zur Energiezufuhr tragen zu seinen einzigartigen Fähigkeiten bei. Der Beitrag beschreibt die Verwendung der Methode der direkten Kollokation zur Optimierung der Trajektorien für das dynamische Verhalten des Roboters und die Stabilisierung dieser Trajektorien mithilfe eines zeitvariablen linearen quadratischen Reglers. Mit RicMonk demonstrieren wir bidirektionales Hangeln und bieten eine vergleichende Analyse mit seinem Vorgänger AcroMonk, einem zweigliedrigen Hangelroboter, um zu zeigen, dass das Vorhandensein eines passiven Schwanzes die Energieeffizienz verbessert. Das Systemdesign, die Steuerungen und die Software-Implementierung sind auf GitHub öffentlich zugänglich.
M-RoCK+VeryHuman: Whole-Body Control of Series-Parallel Hybrid Robots
Das Video illustriert die Ergebnisse der Arbeit Dennis Mronga, Shivesh Kumar, Frank Kirchner: "Whole-Body Control of Series-Parallel Hybrid Robots", Accepted for Publication: IEEE International Conference on Robotics and Automation (ICRA), 23.5.-27.5.2022, Philadelphia, 2022.
RH5: Motion Capture State Feedback für die Echtzeitsteuerung eines humanoiden Roboters
Das Video veranschaulicht die Ergebnisse der Veröffentlichung Mihaela Popescu, Dennis Mronga, Ivan Bergonzani, Shivesh Kumar, Frank Kirchner: "Experimental Investigations into Using Motion Capture State Feedback for Real-Time Control of a Humanoid Robot", zur Veröffentlichung angenommen: MDPI Sensors Journal, Sonderausgabe "Advanced Sensors Technologies Applied in Mobile Robot", 2022.
RH5 Manus: Hintergründe der Robotertanzgenerierung basierend auf musikanalysegesteuerter Trajektorienoptimierung
RH5 Manus: Robotertanzgenerierung basierend auf musikanalysegesteuerter Trajektorienoptimierung
Musikalisches Tanzen ist ein allgegenwärtiges Phänomen in der menschlichen Gesellschaft. Die Fähigkeit von Robotern zu tanzen hat das Potenzial, die Koexistenz von Mensch und Roboter akzeptabler zu machen. Daher haben tanzende Roboter in den letzten Jahren ein erhebliches Forschungsinteresse geweckt. In diesem Beitrag stellen wir eine neuartige Formalisierung des Robotertanzes als Planung und Steuerung von optimal getakteten Aktionen vor, die auf
Taktzeiten und zusätzlichen, aus der Musik extrahierten Merkmalen. Wir zeigen die Anwendung dieser Formulierung in drei verschiedenen Varianten: mit der Eingabe einer Choreografie durch einen menschlichen Experten, der Imitation einer vordefinierten Choreografie und der automatischen Generierung einer neuen Choreografie. Unsere Methode wurde an vier verschiedenen Musikstücken validiert, sowohl in der Simulation als auch an einem realen Roboter, dem humanoiden Oberkörperroboter RH5 Manus.
RH5 Manus: Vorstellung eines leistungsfähigen humanoiden Oberkörperdesigns für dynamische Bewegungen
Jüngste Studien deuten darauf hin, dass eine steife Struktur zusammen mit einer optimalen Massenverteilung die Schlüsseleigenschaften sind, um dynamische Bewegungen auszuführen, und dass parallele Designs einem Roboter diese Eigenschaften verleihen. In dieser Arbeit wird das neue Oberkörperdesign des humanoiden Roboters RH5, genannt RH5 Manus, mit seriell-parallelem Hybriddesign vorgestellt. Die neuen Konstruktionsentscheidungen ermöglichen es uns, dynamische Bewegungen auszuführen, einschließlich Aufgaben, die eine Nutzlast von 4 kg in jeder Hand erfordern,
und schnelle Box-Bewegungen. Die parallele Kinematik in Kombination mit einer seriellen Gesamtkette des Roboters ermöglicht uns eine hohe Krafterzeugung bei einem größeren Bewegungsbereich und einer geringen peripheren Trägheit. Der Roboter ist mit Kraft-Drehmoment-Sensoren, Stereokamera, Laserscannern, hochauflösenden Encodern usw. ausgestattet, die eine Interaktion mit dem Bediener und der Umgebung ermöglichen. Wir generieren verschiedene dynamische Bewegungen mit Hilfe von Bahnoptimierung und führen sie erfolgreich auf dem Roboter mit genauer Bahn- und Geschwindigkeitsverfolgung aus, wobei wir die Grenzen für Rotation, Geschwindigkeit und Drehmoment der Gelenke einhalten.
RH5 Manus: Humanoider Assistenzroboter für zukünftige Weltraummissionen
Der humanoide Roboter "RH5 Manus" wurde im Rahmen des "TransFIT"-Projekts als Assistenzroboter entwickelt, der in der direkten menschlichen Umgebung, zum Beispiel auf einer zukünftigen Mondstation, eingesetzt werden kann. Ziel war es, den Roboter mit den notwendigen Fähigkeiten auszustatten, um komplexe Montagearbeiten sowohl autonom, als auch in Kooperation mit Astronauten und teleoperiert durchzuführen. Ein weiterer Schwerpunkt des Projekts lag auf der Übertragung der entwickelten Technologien auf die industrielle Fertigung und Produktion. Das Video zeigt die mechanische Montage und die Inbetriebnahme des Roboters.
RH5: Entwurf, Analyse und Steuerung des Serien-Parallel-Hybridroboters RH5 Humanoid
In diesem Beitrag wird ein neuartiger seriell-paralleler Hybrid-Humanoid namens RH5 vorgestellt, der 2 m groß ist und nur 62,5 kg wiegt und in der Lage ist, schwere dynamische Aufgaben mit 5 kg Nutzlast in jeder Hand auszuführen. Die Analyse und Steuerung dieses Humanoiden wird mit einer Ganzkörper-Trajektorien-Optimierungstechnik durchgeführt, die auf differentieller dynamischer Programmierung (DDP) basiert. Zusätzlich stellen wir einen verbesserten kontaktstabilitätsabhängigen DDP-Algorithmus vor, der in der Lage ist, physikalisch konsistente Lauftrajektorien für den Humanoiden zu generieren, die über eine einfache PD-Positionskontrolle in einem Physiksimulator verfolgt werden können. Schließlich präsentieren wir erste experimentelle Ergebnisse mit dem humanoiden Roboter RH5.
Torque-limited simple pendulum: A toolkit for getting started with underactuated robotics
This project describes the hardware (Computer-aided design (CAD) models, Bill Of Materials (BOM), etc.) required to build a physical pendulum system and provides the software (Unified Robot Description Format (URDF) models, simulation and controller) to control it. It provides a setup for studying established and novel control methods on a simple torque-limited pendulum, and targets students and beginners of robotic control. In this video we will cover mechanical and electrical setup of the test bed, introduce offline trajectory optimization methods and showcase model-based as well as data-driven controllers. The entire hardware and software description is open-source available.